I still use RSS feeds as my main way of consuming stuff on the internet. Old school. I was looking at the list of things that I've subscribed to which has been imported back from the Google Reader days, and figured I'd do some exploration of ye old OPML file.
Setup the Gemfile
We'll need to pull in a few gems here:
| |
And install everything
| |
Look at domains
First, lets see what we can find out about the machine that hosts the feed. First we see if the hostname resolves, then we pull out the domain from the hostname to see when it was registered.
| |
{:hostname=>"codex.happyfuncorp.com",
:resolved=>"52.6.3.192",
:domain=>"happyfuncorp.com",
:registered=>true,
:created_on=>2010-10-27 19:39:32 UTC,
:updated_on=>2019-10-12 12:39:11 UTC,
:expires_on=>2020-10-27 19:39:32 UTC}
{:hostname=>"aestheticsofjoy.com",
:resolved=>"104.31.75.74",
:domain=>"aestheticsofjoy.com",
:registered=>true,
:created_on=>2009-05-14 04:36:37 UTC,
:updated_on=>nil,
:expires_on=>2021-05-14 04:36:37 UTC}
So this domain has been around for a few years! There's also
.contacts that we in theory could use, but poking around it seems like
things are wrapped up in privacy proxies for the most part.
Reading the OPLM
Lets say that you have a OPML file called feeds.opml. We'll parse the
XML to pull out the awesome that we need.
| |
Which prints out all those old RSS feeds, in all their 375 lines of glory in my case.
Testing loading a Feed
Loading the feed and parsing it is fairly simple using feedjira. We pull in the feed with HTTParty, and just pass the body right into feedjira. One statistic that's interesting is the generator, which is the blogging platform that the person is using. It'll be interesting to see what the world is using.
We also need to deal with the fun world of redirect, so lets put in a bit of logic for that.
| |
Looking for renamed feeds
It's possible that the feed has simply moved and never gotten update.
Perhaps the site is still there serving HTML, but they switch
platforms years ago and the feed url never got updated. So lets go
through all of the output and see for the domains that still resolve
if the root has a link alternative defined inside of the head block
and then try and get that new feed. Who knows what we might discover!
| |
Note that in the first case we pass in a http link which gets updated
to a https served feed, and in the second case it's a relative link
that gets the correct final link.
Looking at http://willschenk.com https://willschenk.com/feed.xml Looking at http://tomcritchlow.com/ http://tomcritchlow.com/feed.xml
Combining everything
The idea here is that we will go through all the feeds and look to see if their domain is still active. If it is, we attempt to pull in the feed to fill in the rest of the information. And from there we can decide what it is that we want to do.
| |
This goes through all of the feeds, so it will take a while to run.
Looking at some stats
Lets look at what the state of my RSS feeds are looking like, here in June of 2020.
| |
Summary
| Total | 358 |
| Resolved | 322 |
| Active with 30 days | 75 |
| Active within a year | 111 |
| Feeds with entries | 222 |
| Total posts | 5708 |
So of the 358 feeds in the file, a whopping 75 are still being updated
and 222 are still on the internet! 111 posting within the last year.
It would be interesting to see when those 75 were first created and
how many posts they have to get a sense of who really is still
publishing with RSS.
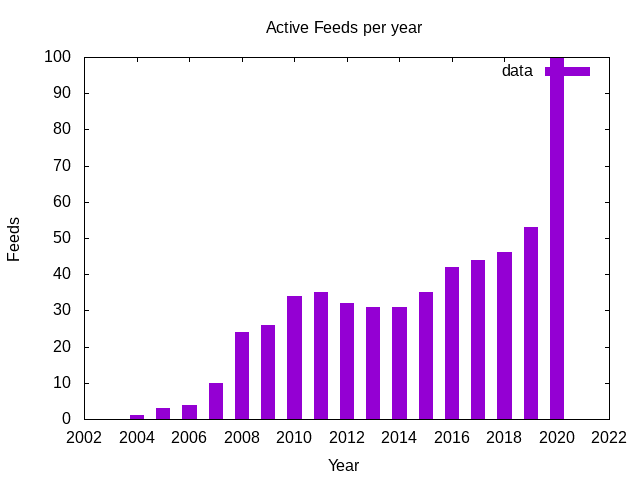
Active each year
Are there more blogs out there in 2016? Did I start reading more then? Interesting that it crept up at this point. But it's also possible that the older subscriptions are part of the internet that disappeared.
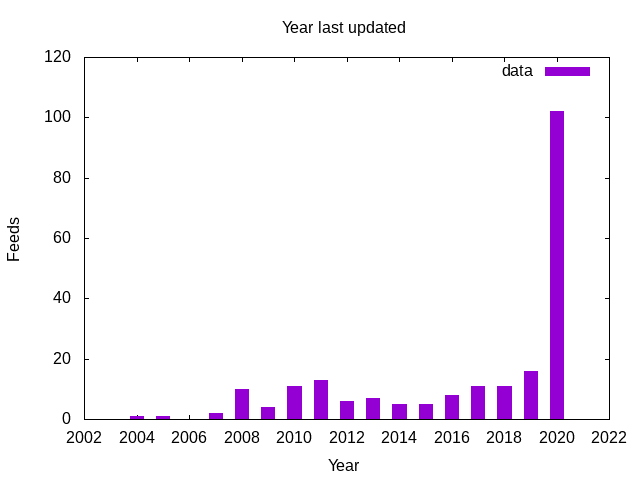
How Old
Looks like a pretty regular number of feeds stop updating every year, though it's been creeping up slowly since 2014.
Generator
As for what people are using (I'm only showing the generators with 2 or more entries), here's a list of the generators for the blogs still actively updating.
| unset | 36 |
| https://wordpress.org/?v=5.4.2 | 16 |
| Hugo – gohugo.io | 7 |
| Tumblr | 6 |
| https://wordpress.org/?v=5.3.4 | 5 |
| Medium | 5 |
| Blogger | 5 |
| http://wordpress.com/ | 4 |
| Jekyll | 3 |
| LiveJournal | 2 |
| https://wordpress.org/?v=5.2.7 | 2 |
What's interesting to me here is:
- Not everyone seems to set a generator, in fact most don't.
- Most are running the latest version of WordPress, but why would it advertise the version number externally? Seems like that might not be the smartest thing since its such a broad attack target.
- Hugo has a much stronger showing than GatbsyJS, but I perceive Gatsby to be more popular in overall front end development. Maybe people just don't make blogs out of it.
- People still use tumblr!
Extracting Active Feeds
My whole goal here was to look for active feeds that I subscribe to
rather than just dumping everything into my elfeed.org file. Lets
write that now (finally!).
| |
Running this yourself
The code for this page is all available in the site's repository. Or
just copy any paste from this page. You'll need an export of your
OPML file, name it feeds.opml, then run ruby feed_checker.rb to scan
through the internet, and ruby stats.rb to summarize the resulting
feed_info.csv file. I like csv for this since you could also easily
import it into Google Sheets and figure out whatever else you want
from it.
